
Implementing effective end-to-end (e2e) tests of conversational AI systems is a major challenge. That’s because applications like voice assistants are nondeterministic in nature and often contain multicomponent architectures, such as:
- Speech-to-text (STT) model
- Large language model (LLM)
- Text-to-speech (TTS) model
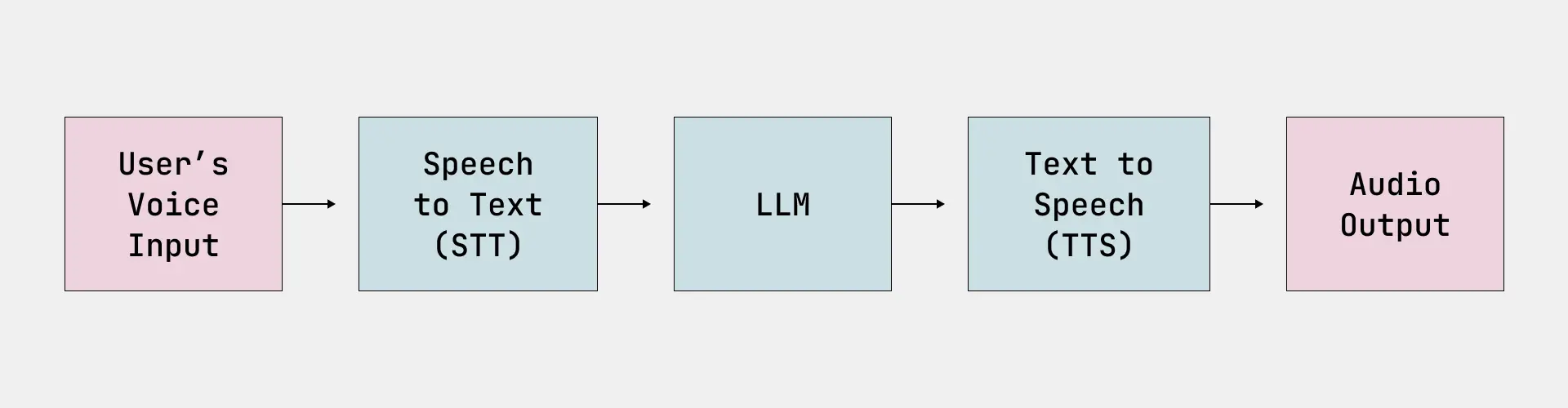
Traditional testing approaches tend to fall short when dealing with the interactions between these components. Though each component should have its own model integration tests, we also need to evaluate the full e2e pipeline of our voice assistant for deeper insights and greater confidence in performance.
In our work building conversational AI systems and testing the best speech-to-text models, we’ve developed a four-step process for evaluating our voice assistant architecture:
- Create a gold standard dataset of user queries and generated responses.
- Generate test audio using a variety of voices, languages, and accents.
- Run tests by feeding the generated audio through our voice assistant.
- Evaluate the outputs by comparing them against our gold standard data.
We’ll walk through these steps using a taco-ordering app as an example, which will serve up the considerations we need to think about when developing an e2e evaluation.
1. Create a Gold Standard Dataset
For our evaluations to be effective, we need to consider the different types of scenarios to target that will give us confidence in our voice assistant. So, for our taco-ordering app, it’s important to factor in things like:
- What types of food can and can’t be ordered
- Our generative artificial intelligence (i.e,. GenAI) policy on what is and isn’t allowed to be talked about
- The different language modalities or phrases we could encounter
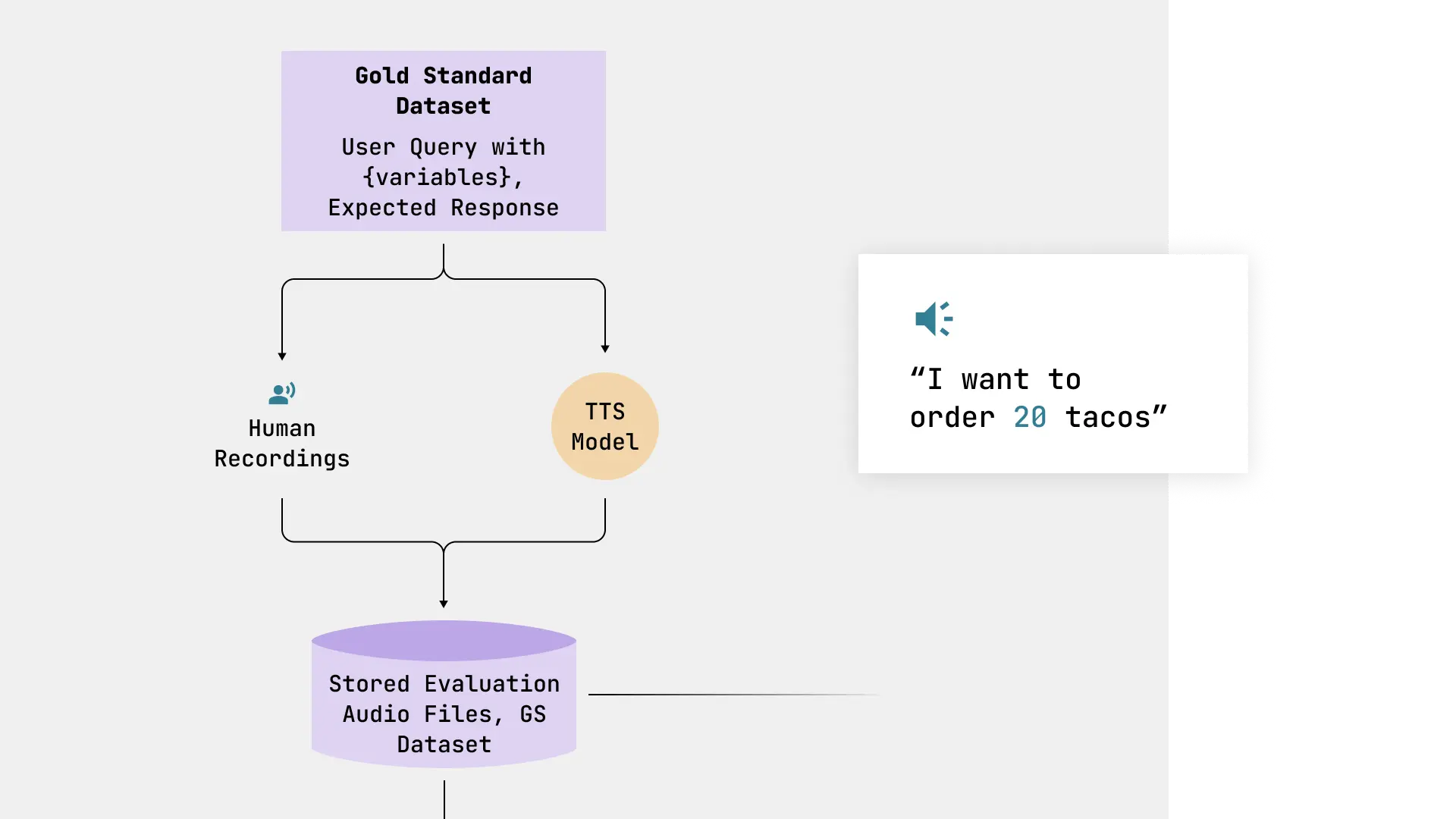
Therefore, our gold standard dataset (i.e., what we will consider our ground truth) should contain `user queries` and `expected responses` at a minimum. It should also include various scenarios (e.g., ordering 20 tacos, negative tacos, unclear quantities) that take into account language variations and policy boundaries.
Here’s how this query and response might flow through our app.
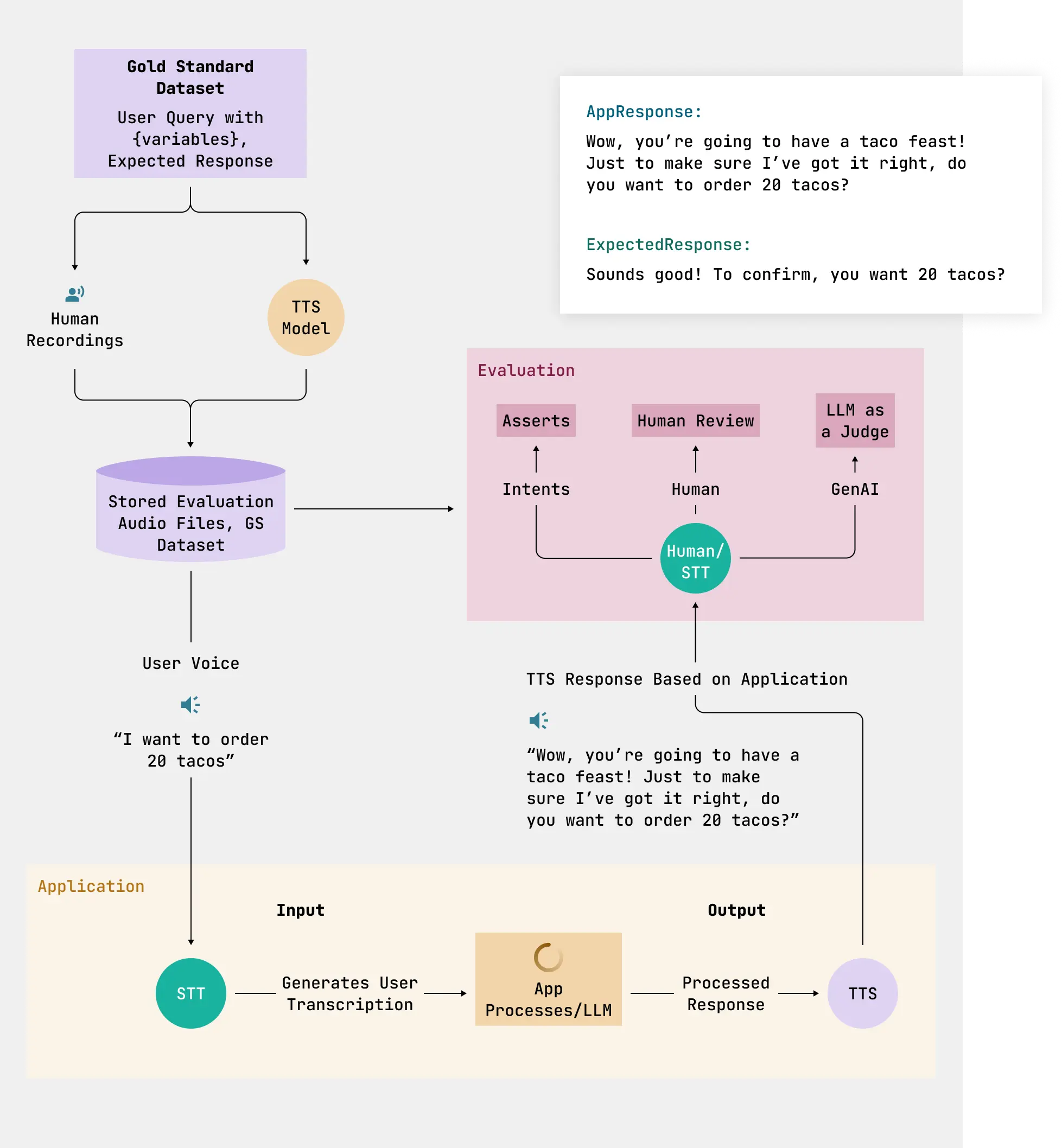
For this approach to work, our gold standard dataset needs at a minimum 1) the user query to be converted to audio and 2) the expected response, which we’ll use to evaluate the app’s generated response against the dataset’s expected response.
2. Generate Test Audio From Expected User Queries
The ‘user query’ scenarios in our gold standard dataset will act as the script to create test audio. This dataset will also allow us to test the STT model in isolation where we can evaluate a given audio file and compare the STT transcription against our gold standard user query.
Once we have the dataset of taco scenarios we want to order through our app, we have two options to generate the audio files:
- Pass our text based `user queries` to humans to record: This is our best option for accent and dialect diversity.
- Use a TTS model to generate synthetic voices to record: This is the faster option, good for small teams to produce diverse datasets quickly.
TTS models are rapidly improving in their ability to do things like speech flow matching, changing emotions, and adding accents. Still, human recordings are preferred for capturing natural speech variations. That approach takes more time and effort than generating synthetic voices though. Data annotation services, specifically audio labeling and dataset creation, can be a big help for recording lots of different human speakers quickly.
Regardless of how the audio is generated, we need to make sure that we have multiple voices and accents, and that we handle different languages effectively. Therefore, it’s worth calling out some common mistakes when developing test audio and how to solve them.
Common pitfalls when developing test audio for conversational AI
Capturing as many different voices as possible is key to testing our app before it’s released. So is factoring in performance issues (e.g., connection quality and background noise). With that in mind, we need to watch out for these pitfalls when generating our test audio:
- Overlooking diversity: Many teams fail to include sufficient diversity in their test data, leading to bias and poor performance for certain user groups. Solution: Actively seek out diverse voices and accents for your dataset.
- Neglecting edge cases: It’s easy to focus on common scenarios and miss unusual but important cases. Solution: Brainstorm potential edge cases and include them in your testing suite.
- Overreliance on synthetic data: While convenient, synthetic data can miss real-world speech nuances. Solution: Balance synthetic data with real human recordings.
- Ignoring environmental factors: Background noise, poor connections, or device variations can significantly impact performance. Solution: Include various environmental conditions in your testing scenarios.
- Failing to update tests: As your AI model evolves, your tests need to evolve too. Solution: Regularly review and update your test suite to match your current AI capabilities and user expectations.
By proactively implementing solutions to these common problems, we’ll enhance our voice assistant’s speech recognition and its ability to carry out voice commands, leading to a better user experience.
3. Run Tests Using the Generated Audio Inputs
Using our diverse set of audio files as input, we send it through our taco app’s voice assistant to act as an e2e test. Now we have the different scenarios we want to test against our gold standard dataset. Because of the different ways and architectures that could be used, we’ll show just an example app call by iterating over our dataset and sending in the audio file to get back an app response.
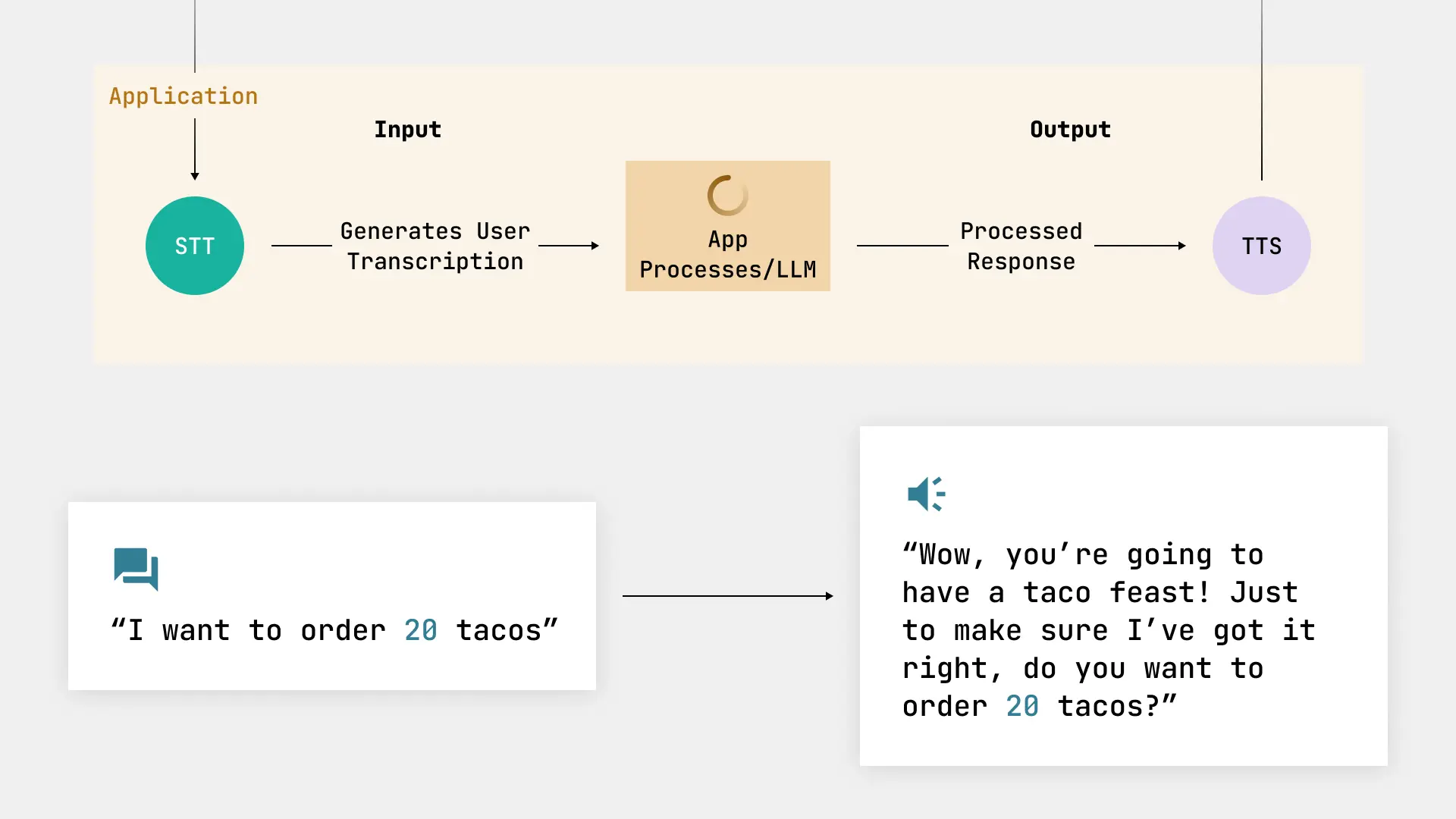
Our app is designed to take in a user’s taco request and ask to confirm the taco count prior to ordering. The LLM will respond based on three different states:
- Taco count above zero
- Taco count that is negative
- Unknown taco count
Once we’ve run all of our test inputs and captured the responses (either text copies of the LLM responses or simply the voice responses), we can compare them against the expected results in our gold standard dataset.
4. Evaluate Test Results
Now we can compare the app’s generated response to the expected response in our original dataset either manually or subjectively. This looks like:
- For fixed responses (Intents): Use direct assertions.
- For GenAI responses: Use an LLM-as-a-Judge metric for semantic evaluation, and assertions for specific elements (e.g., number of tacos). Note we still need to include human review, especially during prompt development.
So how do we know which to use? Here’s a good way to think about it. If the app process only ever returns fixed responses, we can pass them into asserts. But if we use GenAI to change and guide our discussion, we can use a mixture of asserts and LLM-as-a-Judge to evaluate the responses (more on using LLM-as-a-Judge in the next section).
As for getting the output from our application, we have a few different options. Depending on the app, we may get either a synthetic voice, just the text, or both. Because this is an e2e test, we can focus on voice. To do this, we can use a local STT model to take the audio output from our app and turn it into text for our evaluation. We can also use just the LLM response text if that is given as well. We can then use a local Whisper model of STT API to convert the speech back into text, using that for evaluations going forward.
LLM-as-a-Judge metric
With the output as text, we can now evaluate the audio output we got from the app. We’ll use LLM-as-a-Judge to quickly give a score of 0 or 1, plus an explanation of the score based on the following prompt below. Note some of the evaluation prompt took the application’s system prompt into consideration (hint hint, this will be important to keep in mind when we review the results).
Now let’s evaluate the responses to our three test queries.
Evaluation output
1. “Order 20 tacos please”
LLM-as-a-Judge review: ✅
Human review: ✅
From the results for “Order 20 tacos please,” we see a score of 1. We expected a confirmation asking if we really wanted 20 tacos. The app responded with a humorous phrase and also asked to confirm the taco count before ordering.
This conforms with expected behavior and points towards the app’s system prompt and evaluation prompt being aligned.
This is a perfect example of ensuring that our prompts make sense, and why having a human review these details early on is a must.
2. “Order negative 1 tacos please”
LLM as a Judge Review: ❌
Human Review: ❌
For “Order negative 1 tacos please,” our app responded correctly based on the app system prompt. But our dataset’s expected response doesn’t match. If we look at the evaluation prompt, we have a line calling out a humorous line about negative tacos: “If the user orders a negative number of tacos, the response should inform the user that they cannot order a negative number of tacos. A negative number must say something close to the humorous phrase ‘No one needs negative tacos.’”
This highlights that we need to update our app’s system prompt to have the appropriate expected response, a humorous line to the effect of “No one needs negative tacos.” Clearly a business requirement is missing, so this is a good catch. Now we can update our application’s system prompt.
But that’s not the only problem here. We should also double check our evaluation prompt and that it specifically calls out the need to address “negative tacos,” because no one wants that.
3. “Order all the tacos please”
LLM-as-a-Judge review: ✅
Human review: ✅
In this case of “Order all the tacos please,” it seems our evaluations are on point. While our expected response is very short, the app response captures not understanding the user’s quantity, and even asks to specify the quantity.
Storing results
Having a place to store these results over time is the aim of LLMOps and good system health. We should set up a system for sharing these results and providing human feedback. Also keep in mind how changes to our prompts will affect our voice assistant’s responses, as well as evaluation output and metrics.
Therefore, we should version our prompts and datasets when running evaluations. Having an evaluation set up will allow us to address changes over time and feel confident about our GenAI application responses.
Keep Fine-Tuning Your Voice-Powered Experiences
With ongoing prompt engineering and good dataset management, we will get our taco app ready for even more orders. Remember that we need to monitor the outputs of our evaluations over time. Human review is necessary when tweaking prompts and ensuring results, especially early on as prompts are changing. With just the simple evaluation and review we conducted above, we’ve already found several places for prompt improvements and dataset health.
As voice pipelines become more common in conversational and GenAI applications, understanding how to test the full user-voice-to-app-to-voice interaction is critical. The four-step process we’ve outlined shows what to expect when evaluating these complex systems. Implementing thorough e2e testing results in more reliable, responsive, and user-friendly voice-enabled applications. This doesn’t mean we shouldn’t test each of our components separately. That said, an e2e approach gives us even greater insight and confidence into the health of the full voice pipeline.
Keep learning how to build engaging voice experiences with more content from WillowTree:
- How to Train AI Voice Tools to Speak Your Customers’ Language
- 7 UX/UI Rules for Designing a Conversational AI Assistant
- ChatGPT Advanced Voice Mode: The Future of AI-Powered Conversations Is Here
And if you need help building, testing, or optimizing your voice applications, take a look at our conversational AI and voice technology consulting services.
