


When building any user-facing generative AI system powered by a large language model or LLM (e.g., a retrieval augmented generation or RAG system), one of our biggest challenges is avoiding AI hallucinations, irrelevant responses, and jailbreaks. Equally important is ensuring the system only provides responses that comply with organizational policies.
The Data and AI Research Team (DART) here at WillowTree is constantly researching ways to prevent harmful outputs from our clients’ LLM systems (e.g., as the result of a jailbreak). In doing so, we devised a strategy for LLM moderation: Use one LLM to filter and moderate the content generated by another LLM.
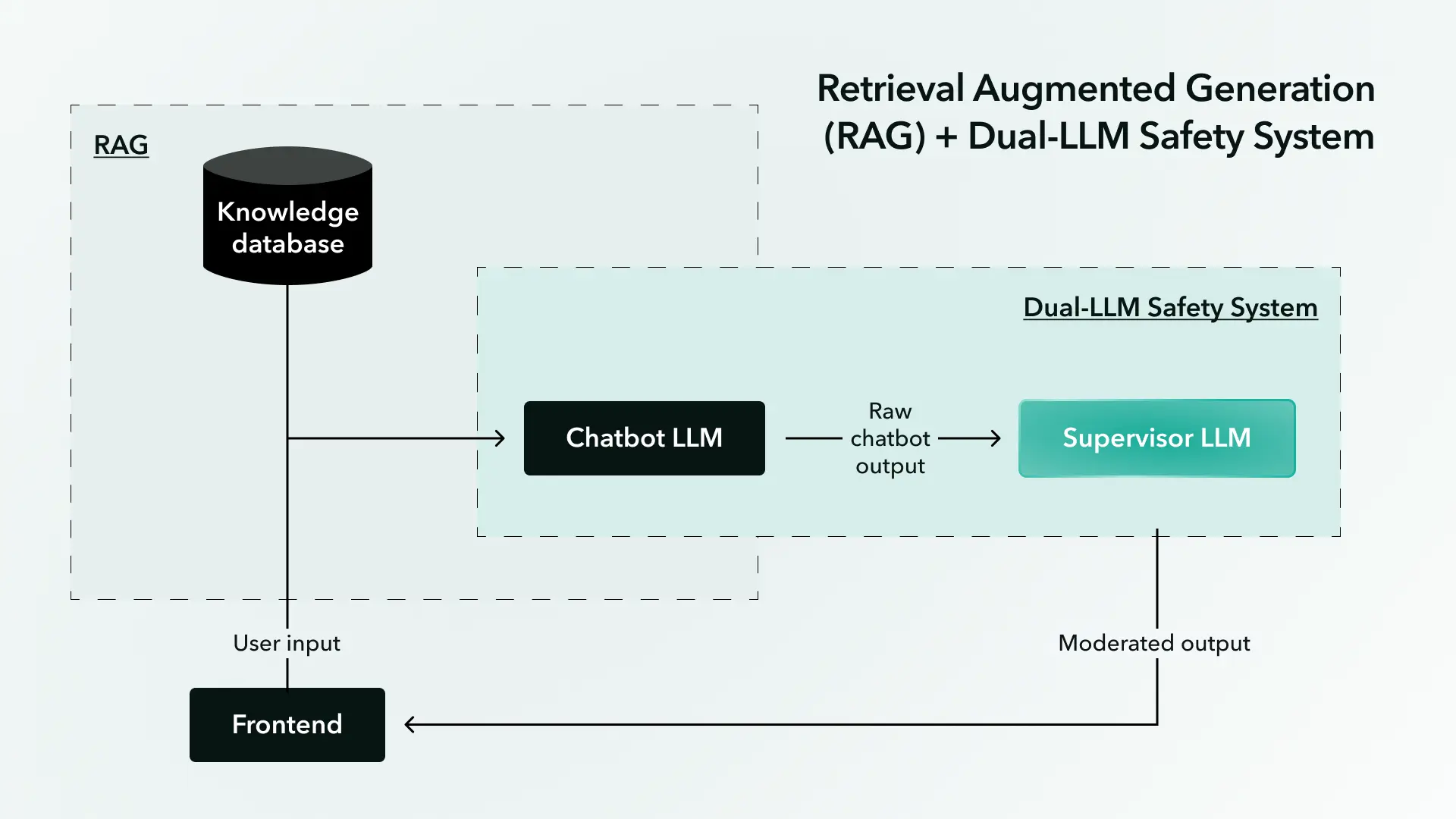
We call this component of our Dual-LLM Safety System: “Supervisor” LLM moderation. Let’s look at how this modular layer of a second supervising LLM works, followed by the experiment results that convinced us the Supervisor LLM approach would safeguard our clients’ generative AI systems.
What is Supervisor LLM Moderation?
The “Supervisor” is an LLM that must determine if the output of another LLM complies with a set of guidelines (i.e., moderate the other LLM’s content). End users will only see the LLM’s output so long as the supervising LLM deems it compliant with a set of guidelines provided via a prompt.
When we first came up with the idea of using LLMs as content filters and moderators, we quickly realized that asking our supervising LLM to classify malicious inputs was futile. The Supervisor LLM itself could be jailbroken in such a way that it wrongly classifies the input.
However, we found that by asking the Supervisor LLM to only examine the direct output of another LLM rather than the potentially malicious user input, the Supervisor LLM was far less likely to be jailbroken.
Furthermore, LLMs excel when given focused tasks. Outsourcing the responsibility of determining response compliance to a dedicated LLM call has proven very effective for our clients’ use cases.
A final benefit: Instead of creating or training a custom classifier system to categorize LLM outputs as compliant/noncompliant, using a Supervisor LLM to do this job is more flexible and easier to implement. There’s no need for a robust training data set, and changes to guidelines/policies only require an update to the prompt of the supervising LLM rather than retraining the model.
How Supervisor LLM Moderation Works
Supervisor LLM moderation is merely an additional LLM call that’s invoked when your generative AI system produces an output. To showcase this, let’s use the example of a financial services conversational AI assistant for the fictional bank, “XYZ Bank.”
To ensure the AI assistant’s response is compliant with XYZ Bank’s policies, we’ll use the following prompt for the Supervisor LLM:
Figure 1.0 - Main supervisor prompt
Note that in this example, we only have the LLM respond with either “True” or “False.” This binary approach minimizes latency and allows us to parse the string value in our code into a boolean and use that boolean in logic — for example, deciding whether to replace the original AI assistant’s response with something safe if the original response is non-compliant.
Next, we must pass in text content for the Supervisor LLM to evaluate. Let’s say the user asks a question about the interest rate for a checking account. The AI assistant for XYZ Bank will produce a response, but before the response reaches the user, it will go to the Supervisor. An example using OpenAI’s chat completion is shown below:
In this case, the value of “response_is_compliant” should be “True.” This value means the original output from the AI assistant’s LLM passes our Supervisor LLM’s guidelines and may be shown to the user.
If we were to pass in any text content that does not adhere to even one of the policies, it should return ‘False.’ See examples below of text content that the supervisor might deem non-compliant:
When the Supervisor LLM finds a noncompliant response
If the value of “response_is_compliant” is ‘False,’ what should the system do? One strategy is simply ending the conversation between the AI assistant and the user. But this abrupt end would violate core UX/UI rules of conversational AI assistant design, especially if the input that caused the non-compliant LLM response was not intentionally malicious.
An alternative strategy is to return a predetermined response to the user instead of the LLM-generated response. For instance:
The advantage of canned responses is they allow the conversation to continue while also serving the dual purpose of providing few-shot examples to the AI assistant’s LLM for how to respond when it receives either intentionally malicious inputs or innocent inputs that lead to non-compliant responses.
However, the disadvantage of a canned response is that it may not fit or flow optimally in the conversation. If this disadvantage is a dealbreaker, another LLM call could conceivably create or select a safer, more appropriate response for the specific conversation.
Strategy and Results from Testing Supervisor LLM Moderation
The Supervisor LLM concept sounded great in theory, but how could we measure if it performed well enough to protect our clients’ generative AI systems? We devised this experiment to see how it operated in practice.
Let’s say the Supervisor LLM must ensure that a piece of text complies with guidelines A, B, and C. An LLM output can be either compliant or non-compliant with each guideline. Since there are three guidelines in this case, there are 23 = 8 possible combinations of input types that the supervisor must be prepared to analyze and judge correctly.
Here’s a partial enumeration of the possible types of inputs and the corresponding expected judgments the Supervisor LLM must be prepared to handle:
To prove the efficacy of the Supervisor LLM, we ran multiple experiments where we generated multiple examples for each combination of violations, then had the Supervisor LLM analyze those examples so we could verify how often its compliance judgments were right or wrong.
Generating experiment data
To generate the data for our experiments, we first generated a set of all possible combinations of guidelines where the various original guidelines were logically negated. For instance, a single combination with some logically negated guidelines could look like the following (negated guidelines emphasized for clarity):
Once we have all the possible combinations of guidelines, we can either manually write up example LLM outputs that fit the description of each combination or use GPT to generate them for us.
Our team tested a Supervisor prompt with six different guidelines, meaning there were 26 = 64 different combinations of inputs. Given that we wanted to test multiple examples per combination, we relied heavily on GPT-4 to generate this data. Here’s an example of the data-generation prompt we used:
Now, here’s an example of the combination and the corresponding output we got from the above data generation step:
Once we completed the data generation, we took all the answers from the question/answer pairs and ran them through the Supervisor LLM to test whether it correctly judged the responses as compliant/non-compliant.
Efficacy experiment results
For each experiment, we used the simple Supervisor prompt shown in Figure 1.0 (see “How Supervisor LLM Moderation Works” section above). Notably, none of the experiments used any other prompt engineering techniques like chain-of-thought (CoT) or few-shot prompting. Correctness was judged solely based on whether or not the Supervisor LLM returned True/False as expected.
Here are the results from our experiments:

As we can see, with the guidelines and prompt shown in Figure 1.0, the Supervisor LLM works remarkably well. Furthermore, all of the incorrect responses given by GPT-3.5 in Experiment #2 occurred with answers that could have debatably been considered either compliant or non-compliant, depending on who you ask.
Other Considerations and Ideas for LLM Moderation
Just as we continue iterating on an AI system well after it’s launched, we also continue iterating on each stage of the process, from benchmarking LLM accuracy to continuously evaluating generative AI performance. This means we will likely keep finding improvements to the Supervisor LLM the more we use it. Two optimizations immediately come to mind: 1) creating an output report to better understand performance and 2) optimizing performance to better handle complex guidelines.
Creating a Supervisor output report
Looking at the efficacy experiments detailed above, observant readers may see potential cases where the Supervisor LLM correctly marks something as non-compliant but because of the wrong guideline.
This issue can be solved by having the Supervisor output a “report” breaking down the compliance of the output for each guideline rather than having it simply return a boolean value. This can be thought of as a somewhat elementary application of the chain-of-thought prompting technique.
We successfully did this by replacing the “INSTRUCTION” in the Figure 1.0 prompt with the following instruction:
Once the output JSON object is parsed, you would simply logical AND all of the boolean values to determine if the response is overall compliant with all of the guidelines.
Improving performance with CoT, few-shot, and sub-supervisors
The technique above could conceivably be improved even further by expanding the CoT. We could have the Supervisor LLM explain the reasoning behind its judgments for each guideline.
Another potential improvement is to provide few-shot examples in the Supervisor LLM call where we’d show inputs along with the correct Supervisor LLM judgment. This may be useful for tricky or complex guidelines. If a database of examples exists, using dynamic few-shot examples may be yet another improvement.
The tradeoff with incorporating CoT or few-shot learning is increased cost and latency.
Last point: if the number or nature of guidelines proves too complex for a single LLM to handle accurately, the task of determining compliance with each guideline can easily be broken down into separate parallelized LLM calls.
Need Help Making Your Generative AI Behave?
The “Supervisor” LLM is a powerful prompt engineering technique. It ensures users interact with your generative AI system safely and securely, congruent with your organization’s policies and guidelines. Despite the Supervisor LLM increasing cost and latency, the tradeoff of preventing undesirable content from reaching users may offer high ROI depending on the use case.
Furthermore, the Supervisor LLM concept can be modified and tailored for any use case, industry, sector, or organization.
It is not, however, a cure-all for the problems inherent to LLMs. Rather, it’s a tool in your toolbox. For instance, we found that by combining the Supervisor LLM with other techniques like intent classification, we can build robust generative AI systems that are compliant and more resistant to malicious inputs and outputs.
If you suspect Supervisor LLM moderation might help mitigate risks in your own system, the WillowTree team can help you customize and apply it to your needs. With our GenAI Jumpstart program, we can fine-tune your existing or prototype a new generative AI system in just eight weeks.
Learn more about the GenAI Jumpstart program.
